Tutorial - Basics 2: Algorithms on Blocks: Sweeps
Table of Contents
Introduces the sweep concept, sweep functions, sweep classes, sweeps on block
In the first tutorial, we set up a domain, build up out of blocks, where each block holds a field data structure. In this tutorial, we are going to write a function that operates on this data. Since the block is the basic unit of our simulation, almost all of our algorithms also work on a single block. This makes it easier to parallelize the program by distributing the blocks to different processes. A function that takes a single block as argument and operates on the block data is called sweep.
For demonstrating how to write a sweep, let us implement the following "algorithm":
- Initialize the scalar field with random values.
- In each time step, double the value in the field if it is bigger than some limit, otherwise halve the value.
Initializing the Field
Using the Initialization Function
In the first tutorial, we initialized the field with zeros using the constructor argument. Now we want to initialize the field with random values. There are two possibilities to achieve that: Since we have the initialization function that creates the field, this is the usual place to perform the initialization:
{
Field<real_t,1> * f = new Field<real_t,1>(
storage->getNumberOfXCells( *block ), // number of cells in x direction for this block
storage->getNumberOfYCells( *block ), // number of cells in y direction for this block
storage->getNumberOfZCells( *block ) ); // number of cells in z direction for this block
for( auto iter = f->begin(); iter != f->end(); ++iter )
(*iter) = real_c( rand() % ARBITRARY_VALUE );
return f;
}
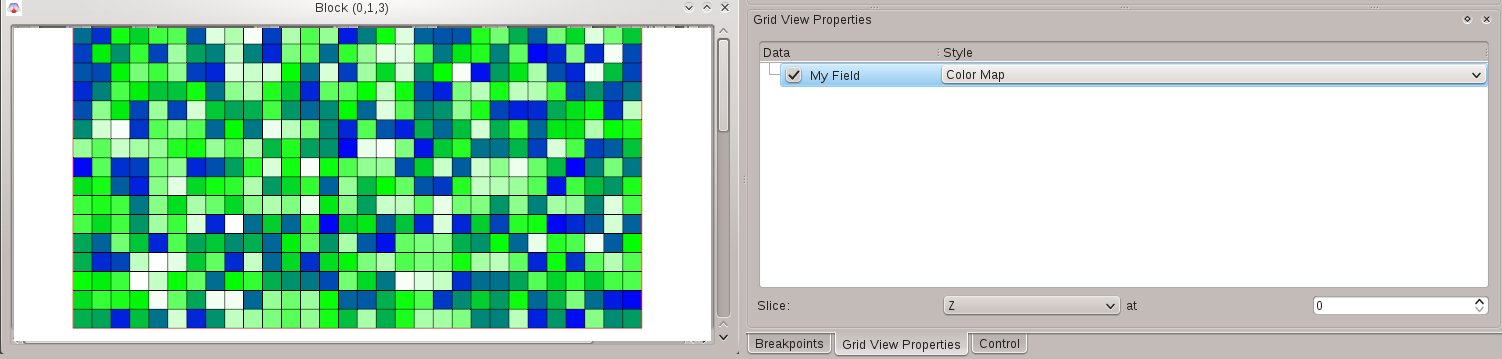
With this, we create an uninitialized field by leaving out the initVal constructor argument. Subsequently, we iterate the complete field and set each cell to some random value. Here is a screenshot of the randomly initialized field using the "Color Map" display style:
Using the BlockStorage to Get All Local Blocks
As we will see later, in most cases, there is no need to write a custom initialization function to add a field to all blocks. So in these cases, the field has to be initialized elsewhere.
We now go back to our original initialization function that initializes the field with zeros and have a look at another option to modify the field.
But how can we access the field that is stored inside a block?
In the main function, we have created a block storage, which holds all the blocks. So the first step is to iterate all blocks. Or more precisely: we iterate all process-local blocks. Since we do that on each process, we end up iterating all blocks in parallel. We can get the field out of every block and finally iterate the field to set the value for each cell.
// add a field to all blocks - and store the returned block data ID which is needed to access the field
BlockDataID fieldID = blocks->addStructuredBlockData< Field<real_t,1> >( &createFields, "My Field" );
// iterate all blocks
for( auto blockIterator = blocks->begin(); blockIterator != blocks->end(); ++blockIterator )
{
IBlock & currentBlock = *blockIterator;
// get the field stored on the current block
Field<real_t,1> * field = currentBlock.getData< Field<real_t,1> >( fieldID );
// iterate over the field and set random values
for( auto iter = field->begin(); iter != field->end(); ++iter )
*iter = real_c( rand() % ARBITRARY_VALUE );
}
Note the first line of the code snippet: when adding the block data, we get back an identifier (handle) which is required to access the added block data later on. In the first tutorial, we did not store this ID.
Having this ID available, we can iterate all blocks using the iterator provided by the block storage. Actually, we are not iterating ALL blocks, but rather only the ones stored locally. Thus when we later distribute the blocks to different processes, every process only iterates its process-local blocks.
Dereferencing the block iterator returns an IBlock, i.e. an object implementing a block interface. If we know the ID and type (!) of a block data item, we can retrieve the data from the IBlock. The IBlock::getData() function takes the BlockDataID of the data that we want to retrieve as an argument, and as a template parameter the type we expect. In principle, one could request a different type as initially stored, however, in debug mode, the error would be detected and the program would terminate.
Register a Function as Sweep
So far, we know how to access blocks and the data stored on them. Hence, we could proceed to the implementation of an algorithm without using the sweep concept or the provided time loop classes.
However, if you use the time loop classes you obtain additional features like the sweep/data selection per block (explained in a later tutorial), automatic time measurement, or time loop control from the GUI.
So let us start with writing our first sweep. A sweep function is a simple function that takes as its only argument an IBlock pointer.
void simpleSweep( IBlock * block )
{
// does not compile since we do not have the fieldBlockDataID here :(
auto field = block->getData< Field<real_t,1> >( fieldBlockDataID );
// some bogus "algorithm"
for( auto iter = field->begin(); iter != field->end(); ++iter )
{
if( *iter > ARBITRARY_VALUE )
*iter /= real_c(2);
else
*iter *= real_c(2);
}
}
There is still a problem with this function: It can only have a single argument, otherwise we can not register it as a sweep at the time loop since we additionally need the BlockDataID of our field. One possibility would be to have a global variable where the BlockDataID is stored (very bad design, do not do that!), or we could use a construct from the standard library called std::bind(). The last can transform a function pointer of a two-argument function to a function pointer of a one-argument function by keeping the second argument constant: It "binds" the second argument to a fixed value.
So we write the function just as we need it:
void simpleSweep( IBlock * block, BlockDataID fieldBlockDataID )
{
// now it compiles :)
auto field = block->getData< Field<real_t,1> >( fieldBlockDataID );
// ...
and register it at the time loop with the following:
SweepTimeloop timeloop( blocks, uint_c(1) );
auto pointerToTwoArgFunction = & simpleSweep;
auto pointerToOneArgFunction = std::bind( pointerToTwoArgFunction, _1, fieldID );
timeloop.add() << Sweep( pointerToOneArgFunction, "BogusAlgorithm" );
Note the strange syntax to add a sweep to the time loop. The add method returns an object (a SweepAdder) where the sweep is piped in. Moreover, in this object e.g. a BeforeFunction or a AfterFunction can be piped in. If you want to know more about the sweep registration read the documentation of timeloop::SweepTimeloop.
Register a Class as Sweep
The variant described above using std::bind() may seem a little strange but there is also another solution. Instead of writing a sweep function, we write a functor class overloading the call operator.
class SimpleSweep
{
public:
SimpleSweep( BlockDataID fieldID )
: fieldID_( fieldID )
{}
void operator()( IBlock * block )
{
// the fieldID is now a member! (was set by the constructor)
auto field = block->getData< Field<real_t,1> >( fieldID_ );
// some bogus "algorithm"
for( auto iter = field->begin(); iter != field->end(); ++iter )
{
if( *iter > ARBITRARY_VALUE )
*iter /= real_c(2);
else
*iter *= real_c(2);
}
}
private:
BlockDataID fieldID_;
};
With this, the registration code does not need std::bind any more:
timeloop.add() << Sweep( SimpleSweep(fieldID), "BogusAlgorithmButNowAsFunctor" );
Note that if you define a member function completely within the class definition, this function is automatically marked as inline. Also, for larger classes, declaring all member functions within the class definition is bad style. Normally, one would have only the function declaration within the class definition. The function is then defined outside of the class:
// class definition including member function declarations (typically inside a header file)
class SimpleSweep
{
public:
SimpleSweep( BlockDataID fieldID )
: fieldID_( fieldID )
{} // note that this is also a function definition within the class, but hey ... ;-)
void operator()( IBlock * block );
private:
BlockDataID fieldID_;
};
...
// definition of the member function (typically inside a *.cpp file - if there are no class or function templates)
void SimpleSweep::operator()( IBlock * block )
{
auto field = block->getData< Field<real_t,1> >( fieldID_ );
for( auto iter = field->begin(); iter != field->end(); ++iter )
{
if( *iter > ARBITRARY_VALUE )
*iter /= real_c(2);
else
*iter *= real_c(2);
}
}
For our small example, however, defining the member function completely within the class definition is fine. Also note that there is only one sweep class but potentially multiple blocks. So members of this class are not block local data!
Using a Sweep on Block
There is a third sweep concept called "Sweep on Block" where the members of the class are in fact block local data.
This is described in more detail here: Sweeps on Block
The next tutorial covers writing a real algorithm, which also requires communication among blocks: Tutorial - Basics 3: Writing a Simple Cellular Automaton in waLBerla
void simpleSweep(IBlock *block, BlockDataID fieldBlockDataID)
Definition: 02_Sweeps.cpp:47
Field< real_t, 1 > * createFields(IBlock *const block, StructuredBlockStorage *const storage)
Definition: 01_BlocksAndFields.cpp:29
FuncCreator< void(IBlock *)> Sweep
Definition: SelectableFunctionCreators.h:133
typename timeloop::SweepTimeloop< > SweepTimeloop
Definition: SweepTimeloop.h:193